Ante cualquier anomalía de red un técnico debe actuar de forma concisa y rápida buscando aislar por completo la fuente de error.
En la mayoría de los casos el primer paso será comprobar el alcance de la anomalía y qué servicios o equipos están inaccesibles debido a ella.
Para poder obtener esta información de forma rápida y más o menos precisa todo técnico de redes dispone de dos herramientas básicas para ello: el ping y el traceroute.
Ping
PING’ el acrónimo de Packet Internet Groper, el que puede significar «Buscador o rastreador de paquetes en redes» es una utilidad que envía paquetes ICMP de solicitud y respuesta y cuya finalidad es comprobar que el equipo destino está activo y disponible. También se puede emplear para obtener la latencia (o tiempo de respuesta RTT) entre dos equipos para tener una noción del retardo existente en la conexión. [fuente: Wikipedia]
Esta utilidad suele venir instalada en la práctica totalidad de sistemas operativos/equipos de red y de ahí que ante cualquier situación problemática con una red podamos hacer uso de ella.
Para poder emplearla bajo sistemas Microsoft Windows deberemos primero lanzar una ventana de MS-DOS:

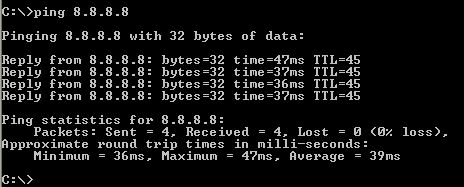
Una vez en ella bastará con que empleemos el comando: ping -equipo-, siendo equipo la dirección IP o el nombre de la máquina (siempre que dispongamos de su traducción DNS correspondiente):
Si el resultado es satisfactorio la respuesta nos dirá además el tiempo de respuesta o latencia y el TTL (Time-to-live). Este último parámetro indica el número de saltos que el paquete ha realizado hasta llegar a destino, pero es un número que depende de otros factores como el tipo de conexión y que explicaremos más adelante.

Si, por el contrario, el equipo no es accesible, la respuesta obtenida será la siguiente.

De este modo con una única utilidad podremos obtener información acerca de la disponibilidad de determinado equipo y, por ende, de determinado servicio.
Traceroute
Traceroute es una utilidad de diagnóstico que permite seguir la pista de los paquetes que vienen desde un host (punto de red). Se obtiene además una estadística del RTT o latencia de red de esos paquetes, lo que viene a ser una estimación de la distancia a la que están los extremos de la comunicación. [fuente: Wikipedia]
En este caso lo que se realizan son llamadas a cada uno de los saltos que realiza el paquete y, por tanto, se nos informa del camino (traza la ruta) que sigue el paquete.
Mediante esta utilidad podemos comprender de forma más coherente el camino que siguen los paquetes e identificar problemas de enrutamiento, balanceo, filtado, etc.
En los sistemas MS Windows la aplicación a emplear es tracert. El procedimiento a seguir es similar, deberemos abrir una ventana de MS DOS y lanzar la aplicación: tracert -equipo-
En la respuesta veremos reflejados todos y cada uno de los saltos que realiza el equipo

Si observamos, algunas líneas muestran * en lugar de valores. Esto se debe a que en ese salto nuestro equipo no ha recibido respuesta del equipo destino: hay varias razones para ello pero entre otras el equipo puede tener deshabilitadas las respuestas por motivos de seguridad.
Generalmente si realizamos esta consulta dentro de nuestra red local deberíamos poder ver todas las respuestas.
Con estas dos utilidades, un técnico de redes puede en cuestión de minutos aislar casi por completo la fuente de error de la red y de este modo enfocar todos sus esfuerzos en resolver el punto de fallo. En entornos donde existen una gran cantidad de equipos de red funcionando resulta fundamental discriminar la mayor cantidad de equipos para poder comenzar con el proceso de análisis con un número de variables reducido.
Deja una respuesta